sharepoint designer(FrontPage)中的正则表达式使用
sharepoint designer中的正则表达式和其他的正则表达不同,开始的时候很折磨人
例如向后引用的分组使用的是大括号{},而不是括号()。
还有其他的不同,如使用#@等符号,:b表示空格,:d表示数等等。。。。
折磨我的那个替换:
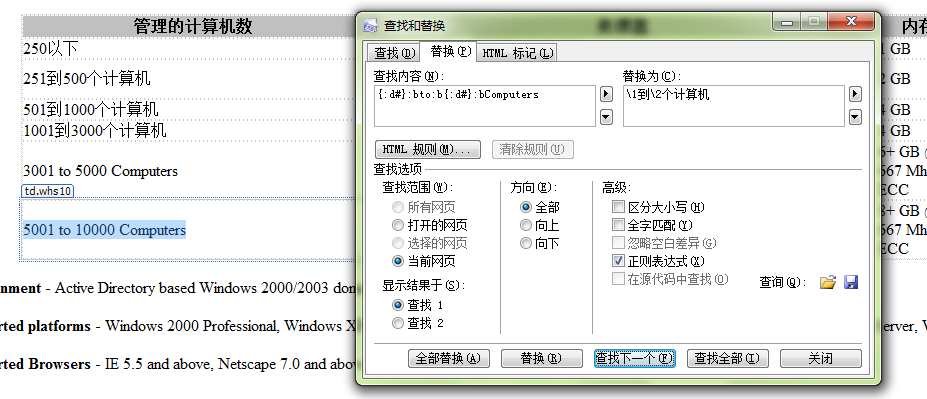
<table class=FTR_TABLE.*\n(^.*$\n)@</table>
这个是一个处理多行的表达式,使用了\n和@
| EXPRESSION | SYNTAX | DESCRIPTION |
|---|---|---|
| Any character | . |
Acts as a wild card to match any single printing or non-printing character with the exception of the newline (\n)character. For example, the regular expressionc.t |
| Maximal — zero or more | * |
Matches zero or more occurrences of a character that precede the expression, matching as many characters as possible. The regular expression.* For example, the regular expression b.*k |
| Maximal — one or more | + |
Matches one or more occurrences of a character that precede the expression, matching as many characters as possible. The regular expression.+ matches
one or more occurrence of one character.For example, the regular expression bo+. |
| Minimal — zero or more | @ |
Matches zero or more occurrences of a character that precede the expression, matching as few characters as possible. The regular expression.@ means
match zero or more occurrences of one character.For example, the regular expression a.@x |
| Minimal — one or more | # |
Matches one or more occurrences of a character that precede the expression, matching as few characters as possible. For example, the regular expressionsi.#er |
| Set of characters | [ ] |
Matches any one of the characters within the brackets ([ ]). You
can specify ranges of characters by using a hyphen (-), as
in [a-z].Examples:
|
| Beginning of line | ^ |
Anchors the match to the beginning of a line. For example, the regular expression^When
in |
| End of line | $ |
Anchors the match to the end of a line. For example, the regular expressionprofessional$ |
| Beginning of file | ^^ |
Anchors the match to the beginning of a file. Works only when searching for text in source code or in text files. For example, to match the first HTML tag at the beginning of a file, use the following regular expression:^^ |
| End of file | $$ |
Anchors the match to the end of a file. Works only when searching for text in source code or in text files. For example, to match the last HTML tag at the end of a file (with no spaces following the tag), use the following regular expression: |
| Or | | |
Indicates a choice between two items, thereby matching the expression before or after the OR symbol (|). For example, the regular expression(him|her) matches
the following occurrences:
but it does not match the line "it belongs to them." |
| Escape special character | \ |
Matches the character following the back slash ( \ ). This allows you to find characters that are used in the regular expression syntax, such as a left curly brace ({) or a caret (^) or some other special character. For example, you can use\$ \. |
| Tagged expression | {} |
Tags the text matched by the enclosed expression. You can match another occurrence of the tagged text in a Find expression or insert the tagged text in a Replace expression using \N. For example, suppose you are looking to find two duplicate, consecutive words. To search, use the following expression:{.#}
\1With the assumption that the consecutive words are separated by a single space, you'll want to add a space between the right curly brace (}) and the back slash ( \ ). In this example, we combine the sharp sign (#) and the period (.) with the curly braces ({}) to make one syntax. In this expression,.# |
| Nth tagged expression | \N |
In a Find expression, \N
In a Replace expression, \N {.#}
\lWith the assumption that the consecutive words are separated by a single space, you'll want to add a space between the right curly brace (}) and the back slash ( \ ). In this example, we combined the sharp sign (#) and the period (.) with the curly braces ({}) to make one syntax. To replace, use the following expression:\l\1 represents what was found in the first pair of curly braces in the find string. By using \1 in the replace action, you essentially replace the duplicate, consecutive words with a single copy of the word. |
| Group expression | ( ) |
Marks the beginning and end of a subexpression. A subexpression is a regular expression that you enclose in parenthesis ( ), such as the expression that follows:(ha)+ This expression matches the following occurrences 'haha' and 'hahaha'. |
| Prevent match | ~x |
Prevents a match
when real~(ity) |
| Line break | \n |
Matches a new line in Code view, or a The syntax (\n), is a shorthand approach to enable you to match all line breaks. |
| Tab | \t |
Matches a single tab character. For example, if you want to find all single tabbed characters at the beginning of a line, the regular expression would look like the following: ^\t+In this example, we combine the caret (^) and the plus sign (+) with the tab (\t) to make one syntax. The caret (^) that precedes the single tab character expression, anchors the match to all tabbed characters at the beginning of the line. The plus sign (+) represents the matching of one or more tab characters. |
| Any one character not in the set | [^] |
Matches any character that is not in the set of characters that follows the caret (^). For example, to match any character except those in the range, use the caret (^) as the first character after the opening bracket. The expression[^269A-Z] |
| Repeat expression | ^n |
Matches [0-9]^4 |
| Alphanumeric character | :a |
Matches the expression [a-zA-Z0-9]. You can use the following expression: [a-zA-Z0-9] :a [a-zA-Z0-9]. |
| White space | :b |
Matches any white spaces in code or text. For example, to match a single white space character at the beginning of a line, use the following regular expression:^:b |
| Alphabetic character | :c |
Matches the expression [a-zA-Z]When
you use this expression, it enables you to match all upper or lower
case letters. You can use the shorthand expression :c [a-zA-Z]. |
| Decimal digit | :d |
Matches the expression[0-9]This
expression enables you to match any digit. For example, suppose you want to find a social security number in a text file. The format for U.S. social security numbers is 999-99-9999. :d^3-:d^2-:d^4 [0-9]^3-[0-9]^2-[0-9]^4]You can use the shorthand expression :d [0-9]. |
| Hexadecimal digit | :h |
Matches the expression [0-9a-fA-F]+Use a this expression when you want to match a hexadecimal combination of any upper or lower case letters between 'A' and 'F', and any numbers. For example, suppose the pages in your Web site have multiple different background colors and you want to change the color of those pages to black, such as 000000. However, you do not know what the hexadecimal numbers are for the existing colors. Use the following regular expression to find all existing hexadecimal numbers: \#:hYou could use [0-9a-fA-F] to search, but in this example we combine the back slash (\) and the sharp sign (#) with the hexadecimal digit (:h) syntax. \# matches a non-expression sharp sign (#) and :h matches any sequence of hexadecimal characters. To replace the existing hexadecimal numbers, type the hexadecimal number of the background color that you want:000000 |
| Identifier | :i |
Matches the expression [a-zA-Z_$][a-zA-Z0-9_$]*When working with code, if you want to match all program identifiers, you can use the shorthand expression :i to
replace having to type the lengthy expression above. |
| Rational number | :n |
Matches the expression ([0-9]+\.[0-9]*)|([0-9]*\.[0-9]+)|([0-9]+)If you want to match all whole numbers that contain a decimal point, you can use the shorthand expression :n |
| Quoted string | :q |
Matches the expression ("[~"]*")|('[~']*')If you want to match all quotes surrounded by quotation marks, you can use the shorthand expression :q |
| Alphabetic string | :w |
Matches the expression [a-zA-Z]+This syntax is a shorthand approach to enable you to match one or more alphabetical characters, either lower case or upper case. |
| Decimal integer | :z |
Matches the expression [0-9]+ This syntax is a shorthand approach to enable you match any number from zero or more. |